
How large language models like GPT-4 can be used to create even more advanced virtual agents
There has been a lot of buzz in the machine learning community recently, particularly around the field of natural language processing and the advancements being made with large language models (LLMs) by companies like OpenAI.
At boost.ai, we are excited about the potential of this technology and have been researching and developing ways to integrate LLMs like GPT-3 and others into our conversational AI platform.
Many companies choose boost.ai for its unparalleled efficiency in quickly improving customer service and internal support. With LLMs, we’re taking this even further—developing more advanced and intelligent virtual agents.
What truly sets us apart is our ability to directly link an LLM to company-specific data, such as a website, and use it to suggest relevant content. This seamless connection enables automated, scalable content recommendations, dramatically accelerating the creation and management of virtual agents.
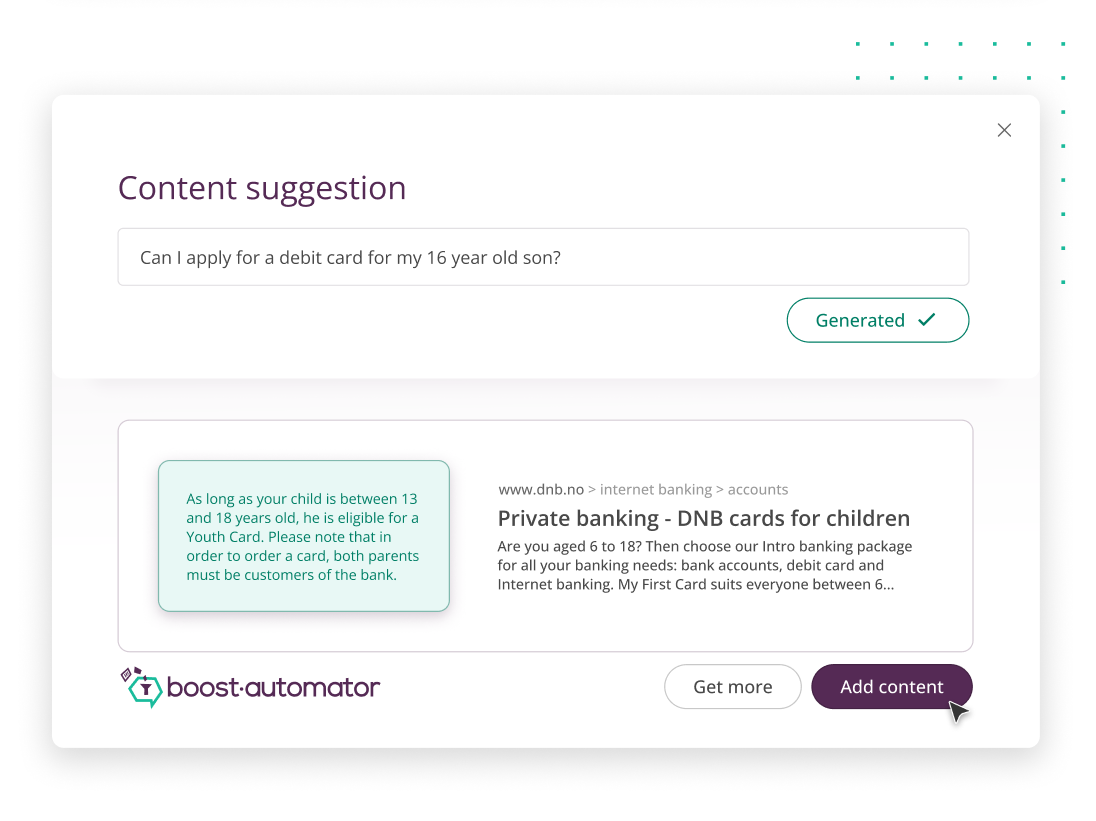
Our customers appreciate the scalability of ourconversational AI— however, creating content for large AI models can be labor-intensive. We can now use LLMs to greatly reduce this workload.
Another important aspect is increasing transparency around the origin of the generated content. Our new Content Suggestion feature (see illustration) displays the source from which the LLM obtained its information, allowing for easier fact-checking and reducing the perception of the model as a "black box."
We are also working to create a content synchronization feature that will automatically update a virtual agent's information when changes are made to the original content source. This is critical for ensuring that the virtual agent always has the most current information, and it also helps to solve the challenge of scaling by making it easier to keep information up-to-date.
This is made possible by our expertise in developing algorithms that rapidly process webpages and information sources. As a result, our conversational AI platform is uniquely designed to connect LLMs with the right data, ensuring exceptional performance for enterprise use cases.
In addition to the above, we will also be adding a number of other features, including using LLMs to automate the creation of training data.
Looking ahead, a big challenge that still needs to be addressed is how to use LLM answers directly with end-users without needing a human-in-the-loop to approve them. The key to achieving this in the future will be to connect the LLM answer with a trustworthy source and figure out a way to verify it with an acceptable level of accuracy. This is the most crucial step in utilizing LLMs in customer-facing applications.
With this figured out, I envision a future where our conversational AI platform fully integrates free-talking language models with its other components, maintaining structure and verifiability. Users could seamlessly switch between conversation flows with LLM-generated answers, various media types, and integrations with APIs and backend systems.
As LLMs become more advanced, it will be important to have a connection to a reliable source to ensure the information they provide is accurate so that their potential can be properly harnessed for use in an enterprise setting.