Chatbots, virtual agents and digital advisors - or whatever you choose to call them - are built to serve the same purpose, but they have to be built with the proper components to successfully deliver lasting business value.
It’s becoming increasingly common to find chatbots and virtual agents taking pride and place over email and phone as a primary method of contact for customers seeking to interact with companies. Many people prefer to use live chat over wading through a website’s confusing FAQs or stunted search functionality, and it’s easy to understand why. Chatting with a robot can quickly and consistently answer customer queries, reducing congestion and freeing up support staff to focus on more pressing tasks.
But the underlying principles of building conversational AI that’s advanced enough to provide actual business value aren’t as simple as the automated, fully-functioning, customer-facing company representative might make it seem. The methods we’ll discuss below are but a few of the prerequisites to successfully deliver a solution far beyond what a simple rule-based chatbot can achieve.
Basic building blocks
Artificial Intelligence Markup Language (AIML) is an XML dialect used to create natural language for virtual assistants. AIML uses a set of rules to define a pattern, whereby if an end-user’s message adheres to said pattern, a rule-based chatbot can elicit a predefined response.

In Figure 1(a), the pattern is defined as ‘HELLO’ and, when triggered by the user, the chatbot replies with the template response ‘Well, hello!’.
Another method for providing a variety of replies to a pattern is through the use of wildcards. These allow for a pattern to be matched, while delivering a seemingly random response from the chatbot.
As evidenced in Figure 1(b), if a user initiates the pattern ‘ONE TIME I *’ by typing in that particular phrase (plus an ensuing qualifier), the chatbot will revert with one of the preset responses at random.

Rule-based chatbots can only serve replies by finding either exact or pattern-based matches for keywords. They are unable to determine how words are connected to each other, let alone the actual meanings of the words themselves.
In the era of artificial intelligence, rule-based chatbots are inadequate at getting the job done efficiently. They may occasionally serve a purpose (in the way that a stopped clock is right twice a day) but ultimately fall short of being truly useful.
To overcome the difficulties of understanding what an end-user actually means, especially if their request is written in a complicated manner, we have to instead look towards artificial intelligence to help solve these problems. At boost.ai, we eschew the use of AIML in favor of deep learning in order to build conversational AI, which is far more advanced than ordinary chatbots.
One million layers
There are a number of simple ways that we can make rule-based chatbots more intelligent, including using word embeddings such as Word2vec, GloVe or fastText, amongst others.
Word embeddings create a vector of 1xN dimensions for each word in a given corpus by using a shallow neural network. While we’ll have to save the particularities of how these vectors are created for another article, it’s important to note, however, that since these embeddings look at how words are used - and what their neighboring words are - they are therefore able to understand the actual meaning of individual words.
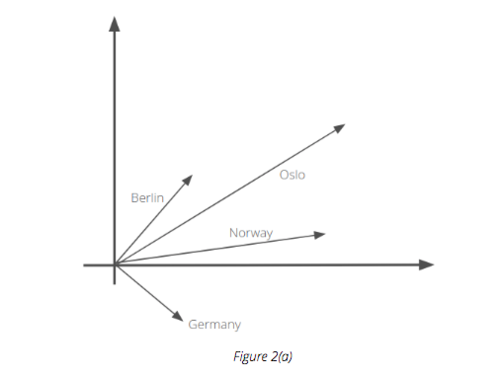
Figure 2(a) represents the vectors for Berlin, Germany, Oslo and Norway across two dimensions. To decompose and represent word vectors in two dimensions, one can use t-Distributed Stochastic Neighbor Embedding (t-SNE) which is a dimensionality reduction technique.
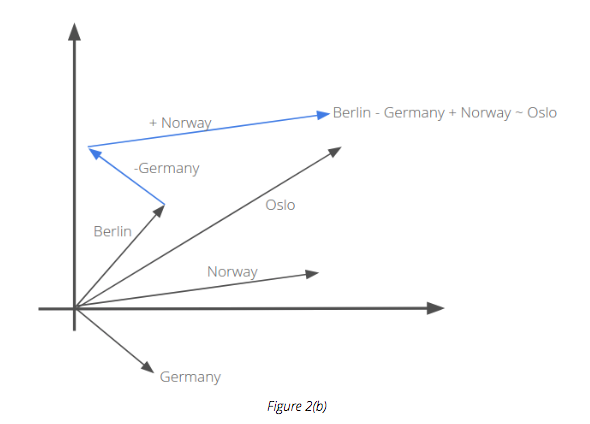
If we subtract the vector for Germany from Berlin and add the vector for Norway, we will get a vector which is very close to the original vector for Oslo.
The word vectors or embeddings can therefore be used to determine the closest words and, using Fasttext techniques, we are also able to derive a vector for word that is not present in the corpus.
Using vectors for words, allow us to build a simple weighted average vector for sentences. Figure 2(c) is a clear example of Python snippet on how to do just that.

Once we have established the vector for the whole sentence, a simple distance metric - such as cosine distance - can be used to find the nearest matching answer for the user’s query, as Figure 2(d) accurately depicts.
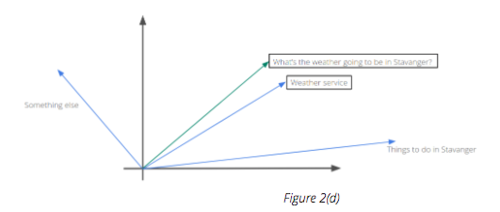
Once we have established the vector for the whole sentence, a simple distance metric - such as cosine distance - can be used to find the nearest matching answer for the user’s query, as Figure 2(d) accurately depicts.
A virtual agent has to contend with a high volume of text-based messages, hence a number of text-processing steps are key to how accurate its responses are. It simply isn’t enough to rely on deep learning models to provide results, as these models will only perform as well as the data given to them.
When drilling down into the Natural Language Processing (NLP) and Natural Language Understanding (NLU) in conversational AI, the following components are the most important:
- Language detection
- Clean up
- Tokenization
- Stemming
- Synonyms & stop words
- Spell correction
- Compound splitting
- Entity recognition
Using these, an intent-based virtual agent should be able to achieve the optimal outcome described in Figure 2(f), with each and every step being crucial to how a VA responds to a message.
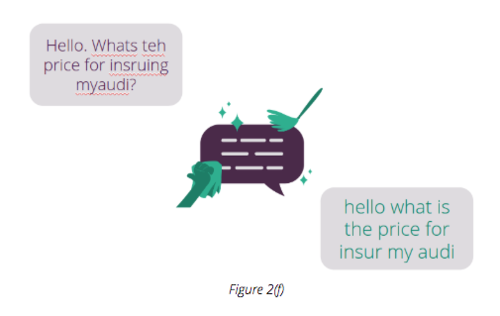
Language detection
There are two options when approaching language detection: either use off-the-shelf libraries such as Langid or fastText, or you can simply build your own. If you decide to go with the latter you can either use a Wikipedia dump for several languages, train a basic TFIDF-Logistic Regression model, or opt for a neural network.
Let’s say we have Wikipedia data for four languages: English, Norwegian, French and German.
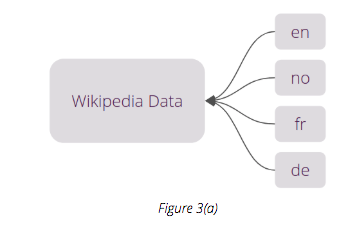
This data can be used with a pipeline consisting of TFIDF and Logistic Regression

The method depicted in Figure 3(b) should provide good results. Alternatively, you could use a simple LSTM-based neural network to achieve the same results.
Clean up
Cleaning up text data in a sentence is a very important task, but it can also be difficult and tiresome.
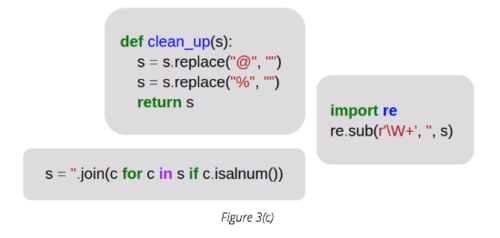
Figure 3(c) illustrates three simple cleanup techniques for how this can be tackled.
It is possible to:
1) replace special characters
2) use a regular expression
3) filter all alphanumeric characters in the sentence
We can mix and match, or try all three of these methods together in order to achieve an optimal result.
Tokenization
The Tokenization step can be applied either before or after clean up. It splits a desired sentence into separate parts called ‘tokens’. While it is commonly believed that Tokenization is principally about separating words by spaces, it is actually language dependant and may require the need to write customized tokenizers if the ones freely-available are not fit for purpose.

Figure 4(a) is an example of how to do Tokenization in Python using the NLTK library.
Stemming
The stemming step is designed to reduce the target word to its base form.
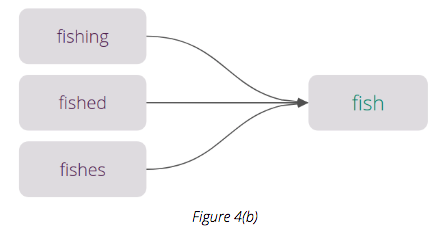
In Figure 4(b), we can see all forms of the word ‘fish’ reduced to a single root word. Rather than confusing a machine learning algorithm with hundreds of variations of a root word, stemming and lemmatization make it easier for an algorithm to understand the root, thus providing optimal results.
Using NLTK, stemming can easily be achieved with the three lines of code illustrated in Figure 4(c).

Synonyms
Understanding a single language is a relatively simple task. When dealing with multiple languages, however, things get more complex. We can use synonyms from different languages to achieve the same result.
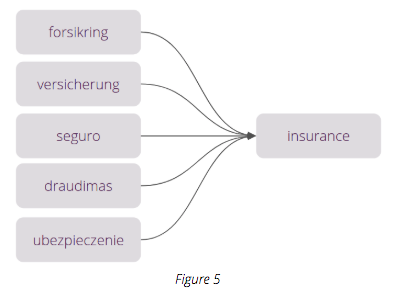
In Figure 5, we see how the conversational AI understands the word ‘insurance’ having been trained with the corresponding word in five different languages. Through this method, it is capable of learning and understanding a higher number of languages than its human counterpart - and way faster too.
Spelling Correction
Dealing with spelling errors is part and parcel of any self-respecting conversational AI. Humans are prone to typos (and we can be guilty, at times, of wanton uses of abbreviation), so we need a strong spelling correction algorithm in place to help sift through the noise of misspelled words.
In order to build a deep learning-based spelling correction model, the following three steps should be adhered to:
- Gather text data from a reliable source (e.g. English Wikipedia Corpus)
- Introduce artificial impurities
- Build a stacked recurrent neural network to distinguish the original sentence from other, impure sentences
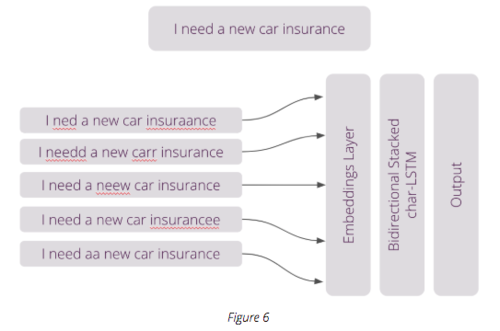
Figure 6 is an example of how a VA can use spelling correction to extract the data it needs from any number of misspelled inputs.
Peter Norvig, a director of research at Google, has an excellent write-up on what goes into writing a spelling corrector that is a good jumping on point for further reading.
Compound splitting
Many European languages have a habit of combining words, which can prove to be tricky for computers to parse. We can use algorithms to help with this, splitting the compound words into smaller parts.
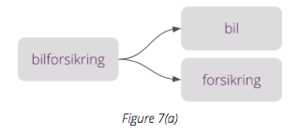
In Figure 7(a), the Norwegian words for ‘car’ and ‘insurance’ are combined to form a single word representing car insurance.
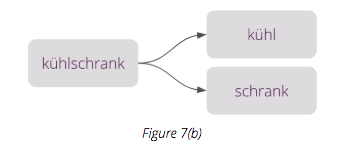
Similarly in German, the word for refrigerator (translated directly as ‘cold cabinet’) is also a single word, as illustrated in Figure 7(b).
We can also treat cases where a user does not correctly use spaces to separate words in a sentence as compound words, such as in Figure 7(c).
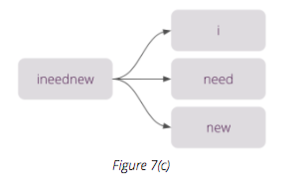
Compound splitting is a crucial and complex challenge that requires thinking about dynamic programming to help reach a worthwhile solution.
Entity recognition
The ability to correctly recognize entities and extract them is a key feature that many lesser solutions fall prey to. Good entity recognition can be achieved in a variety of ways and becomes increasingly important as the conversational AI must understand and extract the pertinent information from within text input by the user.
It can be as simple as extracting ‘to’ and ‘from’ entities using a basic expression:

Or, building a deep neural network with large amounts of data to tag different words in a sentence:
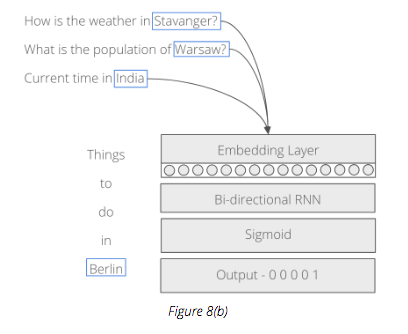
In Figure 8(b), the sentences at the top are the training data. The locations are tagged as ‘1’, while the other words in the sentence bare a tag of ‘0’. If a user inputs a new sentence, e.g ‘Things to do in Berlin’, the network displayed above will be able to correctly identify ‘Berlin’ as a location, providing the appropriate amount of training data has been supplied.
Data and the model
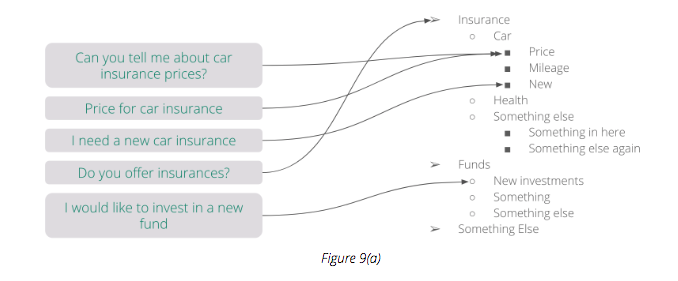
When everything related to text-processing is in place, we can then begin to build an intent classification model. Figure 9(a) illustrates an example of how the data for that model could look like:
For each intent listed in Figure 9(b) (e.g. insurance, car insurance, funds etc.) there is an amount of corresponding training data associated with it. We can apply the same text processing methods discussed previously to the training data and then send it to a deep neural network.
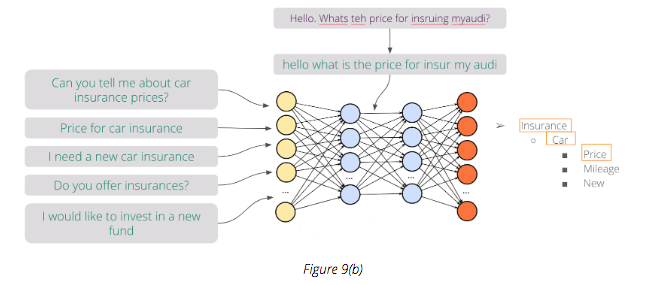
When the user inputs a new sentence, text-processing methods are applied as before and, if everything runs smoothly, the correct intent is predicted by the network and a dynamic response is generated which can then be sent to the end-user.
A good example of this is Figure 9(c) which illustrates a complicated case from one of our live clients.
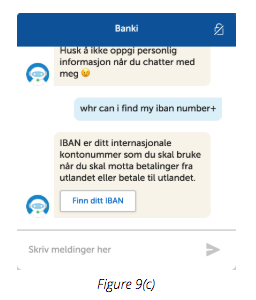
In this example from a Norwegian bank, the primary language is (obviously) Norwegian, whereas the end-user wrote their question in English. Regardless of the input language, Banki, their digital banking advisor, is able to accurately understand the question and serve the correct response, despite different languages and spelling and formatting errors.
With the correct components and training, conversational AI has the capacity to break language barriers, assist end-users, automate processes and digitize customer interaction to a far greater extent than its human counterparts.